Principal component analysis
1 Intuition
Imagine, that you have a dataset of points. Your goal is to choose orthogonal axes, that describe your data the most informative way. To be precise, we choose first axis in such a way, that maximize the variance (expressiveness) of the projected data. All the following axes have to be orthogonal to the previously chosen ones, while satisfy largest possible variance of the projections.
Let’s take a look at the simple 2d data. We have a set of blue points on the plane. We can easily see that the projections on the first axis (red dots) have maximum variance at the final position of the animation. The second (and the last) axis should be orthogonal to the previous one.

This idea could be used in a variety of ways. For example, it might happen, that projection of complex data on the principal plane (only 2 components) bring you enough intuition for clustering. The picture below plots projection of the labeled dataset onto the first to principal components (PCs), we can clearly see, that only two vectors (these PCs) would be enough to differ Finnish people from Italian in particular dataset (celiac disease (Dubois et al. 2010))  source
source
2 Problem
The first component should be defined in order to maximize variance. Suppose, we’ve already normalized the data, i.e. \sum\limits_i a_i = 0, then sample variance will become the sum of all squared projections of data points to our vector {\mathbf{w}}_{(1)}, which implies the following optimization problem:
\mathbf{w}_{(1)}={\underset {\Vert {\mathbf{w}}\Vert =1}{\operatorname{\arg \,max}}}\,\left\{\sum _{i}\left({\mathbf{a}}^{\top}_{(i)}\cdot {\mathbf{w}}\right)^{2}\right\}
or
\mathbf{w}_{(1)}={\underset {\Vert \mathbf{w} \Vert =1}{\operatorname{\arg \,max} }}\,\{\Vert \mathbf{Aw} \Vert ^{2}\}={\underset {\Vert \mathbf{w} \Vert =1}{\operatorname{\arg \,max} }}\,\left\{\mathbf{w}^{\top}\mathbf{A^{\top}} \mathbf{Aw} \right\}
since we are looking for the unit vector, we can reformulate the problem:
\mathbf{w} _{(1)}={\operatorname{\arg \,max} }\,\left\{ \frac{\mathbf{w}^{\top}\mathbf{A^{\top}} \mathbf{Aw} }{\mathbf{w}^{\top}\mathbf{w} }\right\}
It is known, that for positive semidefinite matrix A^\top A such vector is nothing else, but eigenvector of A^\top A, which corresponds to the largest eigenvalue. The following components will give you the same results (eigenvectors).
So, we can conclude, that the following mapping:
\underset{n \times k}{\Pi} = \underset{n \times d}{A} \cdot \underset{d \times k}{W}
describes the projection of data onto the k principal components, where W contains first (by the size of eigenvalues) k eigenvectors of A^\top A.
Now we’ll briefly derive how SVD decomposition could lead us to the PCA.
Firstly, we write down SVD decomposition of our matrix:
A = U \Sigma W^\top
and to its transpose:
\begin{align*} A^\top &= (U \Sigma W^\top)^\top \\ &= (W^\top)^\top \Sigma^\top U^\top \\ &= W \Sigma^\top U^\top \\ &= W \Sigma U^\top \end{align*}
Then, consider matrix A A^\top:
\begin{align*} A^\top A &= (W \Sigma U^\top)(U \Sigma V^\top) \\ &= W \Sigma I \Sigma W^\top \\ &= W \Sigma \Sigma W^\top \\ &= W \Sigma^2 W^\top \end{align*}
Which corresponds to the eigendecomposition of matrix A^\top A, where W stands for the matrix of eigenvectors of A^\top A, while \Sigma^2 contains eigenvalues of A^\top A.
At the end:
\begin{align*} \Pi &= A \cdot W =\\ &= U \Sigma W^\top W = U \Sigma \end{align*}
The latter formula provide us with easy way to compute PCA via SVD with any number of principal components:
\Pi_r = U_r \Sigma_r
3 Examples
3.1 🌼 Iris dataset
Consider the classical Iris dataset
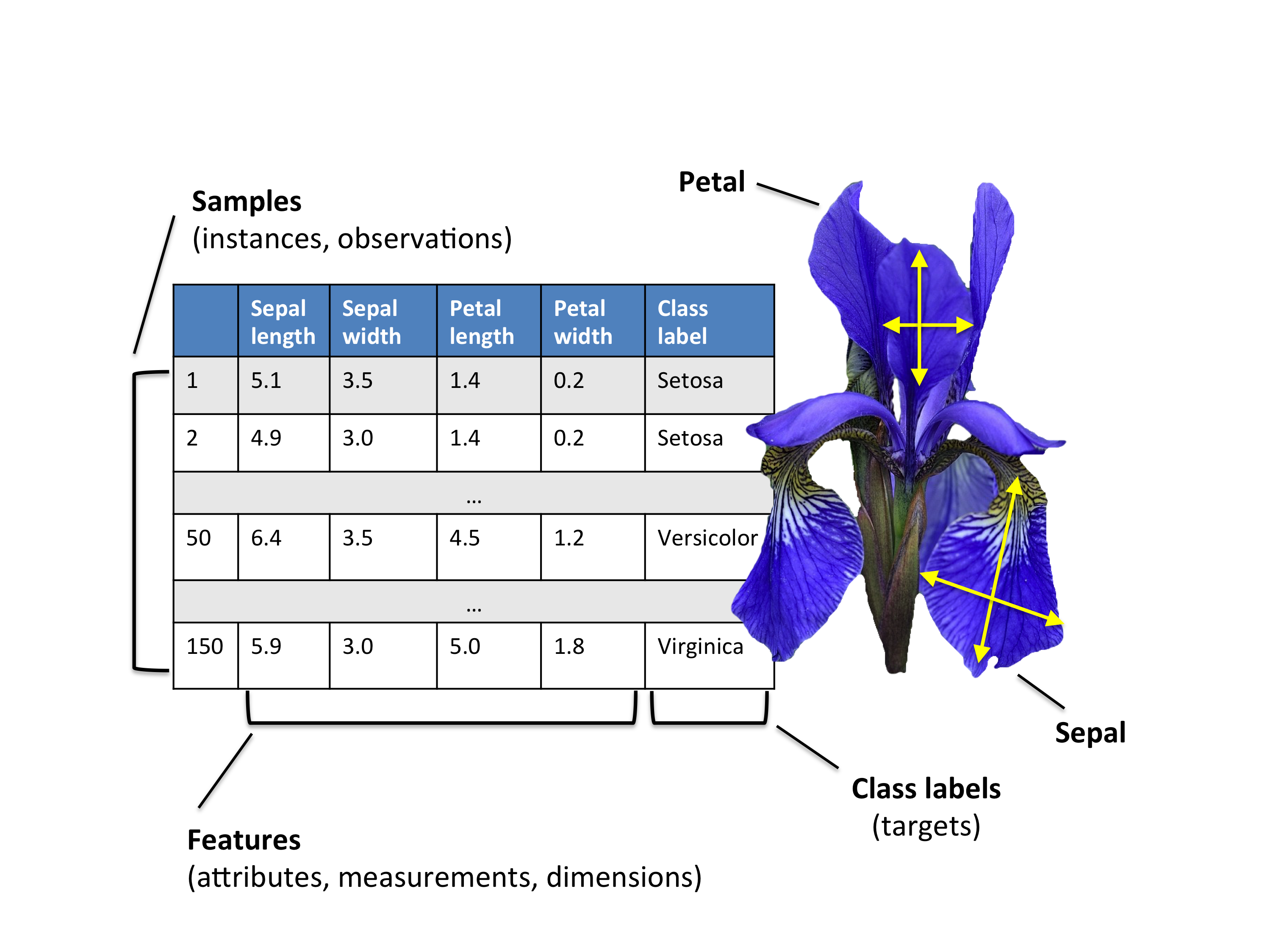
We have the dataset matrix A \in \mathbb{R}^{150 \times 4}


4 Code
Open In Colab{: .btn }